There are two hard problems in software development: packaging, and deployment.
The deployment dilemma
If you write code, sooner or later you’ll probably need to:
- leverage other people’s code
- declare external dependencies
- run your code somewhere other than your dev machine
It turns out this is kind of a hard problem, and new solutions are being invented all the time:
| Misleading Google Search Results | |
|---|---|
| deployment methods | 108,000,000 |
| package managers | 9,080,000 |
Should I use virtual machines? Containers? Do I need configuration management tools? Should I be looking into hosted services in The Cloud? There are no easy answers to these questions, and it takes a lot of time and practice to become familiar with their tradeoffs and choose an appropriate strategy for your project.
But regardless of what you choose, there’s one thing they almost always have in common: packages.
Somewhere along the line your deployment strategy will be improved by being able to install something (build or runtime dependencies, your own code, or even automation tools themselves) if it’s already been packaged up in a way that’s reproducible and reliable.
We’ll show you how you can incorporate the Nix package manager into your workflow in two days with minimal disruption and time. You can start taking advantage of its benefits almost immediately (such as installing multiple packages at once that have conflicting versions or dependencies), but still use it alongside any package managers you’re already using.
Package managers
If you haven’t spent time with Nix, you’re probably wondering why you need a new package manager. We already have apt/yum/homebrew/etc., all with their own approaches, and the whole situation starts to feel a little like…
")
So why bother learning Nix?
Because it is different! It’s based on functional programming concepts and a model that affords it several advantages. Thankfully, the basic features and concepts have already been well covered elsewhere.
I’m hoping that if you’ve made it this far, you already have some interest in it. If you’re skeptical about getting started right away, I recommend spending some time reading the above links to get a better sense of what Nix offers.
The “two days” recommendation is a suggestion for pacing so you don’t need to dive too deep down the Nix rabbit hole on the first day you try it out, but the actual steps we’ll go over could be run through much faster if desired.
Day 1: Installation
Good news! It’s not going to take a day to install Nix (the quickstart install takes a few minutes at most), but we’ll go at a slower pace here so you can spend time learning the basic tools and some of the concepts too.
One of Nix’s defining features is the packages it builds will not depend on global install directories (/bin, /usr, /lib, etc), and the packages will be placed in the /nix/store. This makes it easy to use alongside existing package managers, because it will not influence or depend on your globally installed packages.1
For Linux or Mac OS X users, the official installation instructions are available on http://nixos.org/nix/. Here’s the short version as of January 2015:
$ curl https://nixos.org/nix/install | sh
$ source ~/.nix-profile/etc/profile.d/nix.shThe first step will set up the /nix/store and install utilities like nix-env that you will use to manage Nix. If you’re concerned about relying on curl for the install you can read the installation chapter of the manual for further options.
The second step will source a shell script that will export your $NIX_PATH and modify your user’s $PATH so it can find utilities installed by Nix.
To search for packages, you can use nix-env -q and grep to filter the results. Here’s a quick example that will run a query (flag q) for packages available (flag a) on your platform, including the package’s attribute path (flag P). We’ll grep for the cowsay package, because who wouldn’t want cowsay:
nix-env -qaP | grep -i cowsay
nixpkgs.cowsay cowsay-3.03Now you can either install by name (from the right hand column in our search results):
nix-env -i cowsay-3.03Or by attribute path (as shown in the left hand column of our earlier search results). Note that we have to add the flag A to indicate we’re installing by attribute:
nix-env -iA nixpkgs.cowsayCongratulations! You’ve installed your first package with Nix. If you aren’t sure what to do next, try out nix-env -i nix-repl. This will install the nix-repl utility that will let you write Nix expressions and interact with Nix in a shell. Examples and getting started instructions for nix-repl are available here.
You’re now free to install packages without breaking system packages, without obscure failures due to changed or missing global dependencies2, and without dependency hell.3
Day 2: myEnvFun
There are a lot of Nix features that have improved my development workflow, and it’s very hard to pick just one to cover here. But time and time again, one of the most useful for me has been myEnvFun, which also shows how we can go beyond typical definitions of “package” to solve common development problems.
Note: the “Fun” in
myEnvFunis for functional. The Nix and NixOS communities make no claims or guarantees of enjoyment derived from using it.
One of the (many) complications in software development is identifying and isolating all of the tools you need to work on a particular project. This isn’t always the case: I usually want tmux and my favorite editor available regardless of what project I’m working on. But other times you might have projects that require conflicting versions of software, like two or more haskell projects using two or more versions of the compiler ghc.
What we’d like to do is define and codify these different environments as package sets containing all the tools we need, preferably giving us some quick and easy way to switch between them.
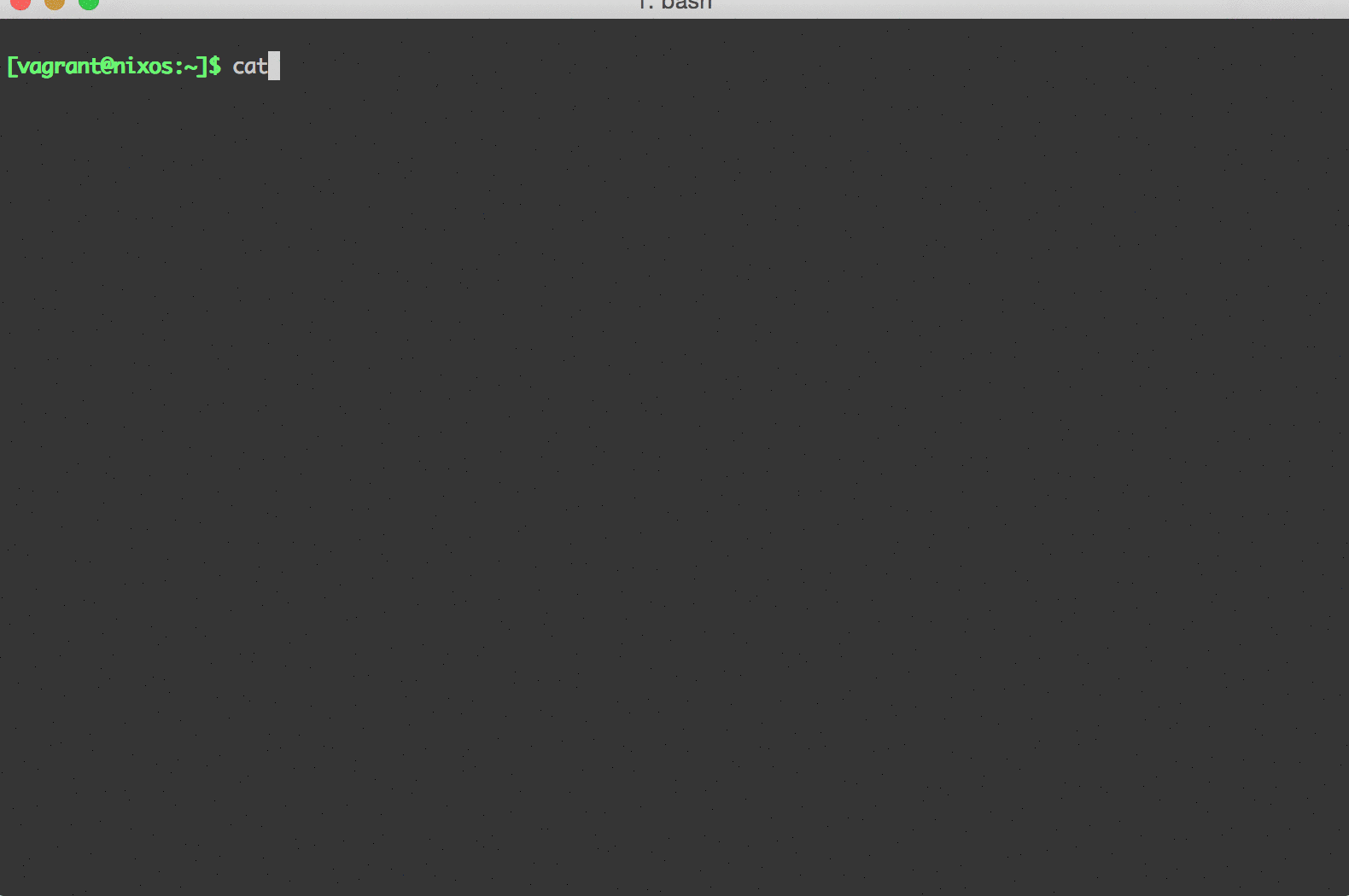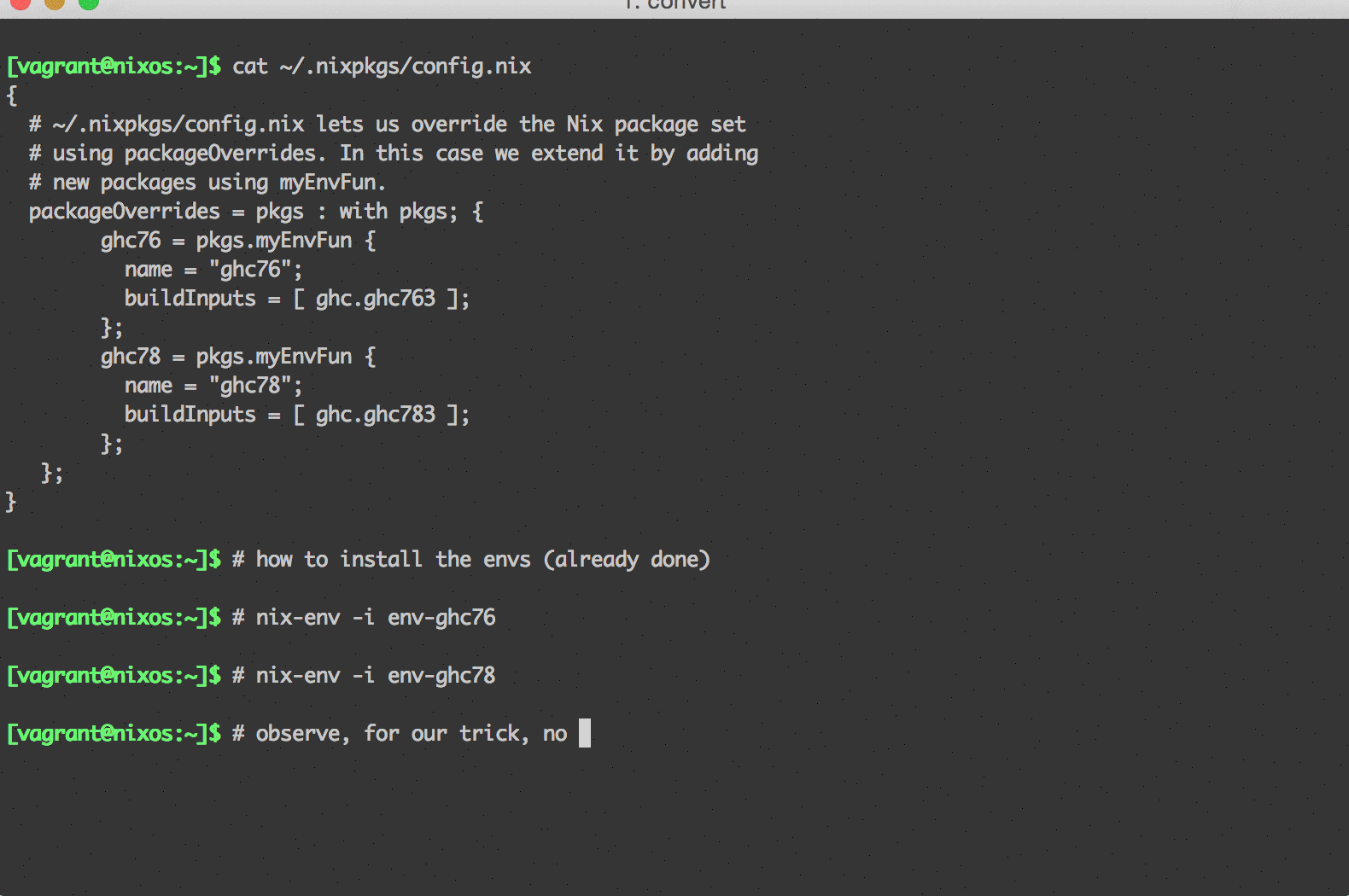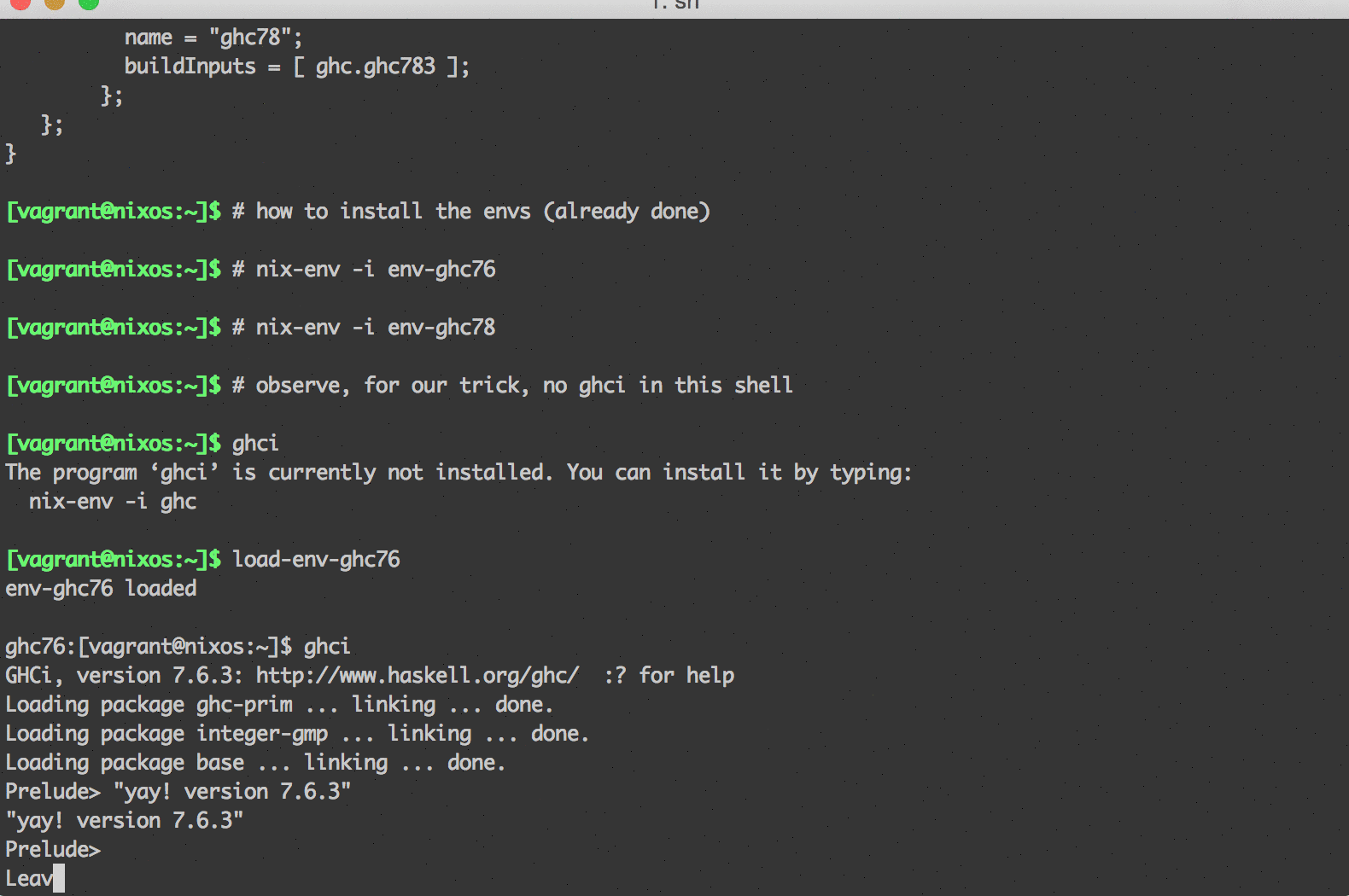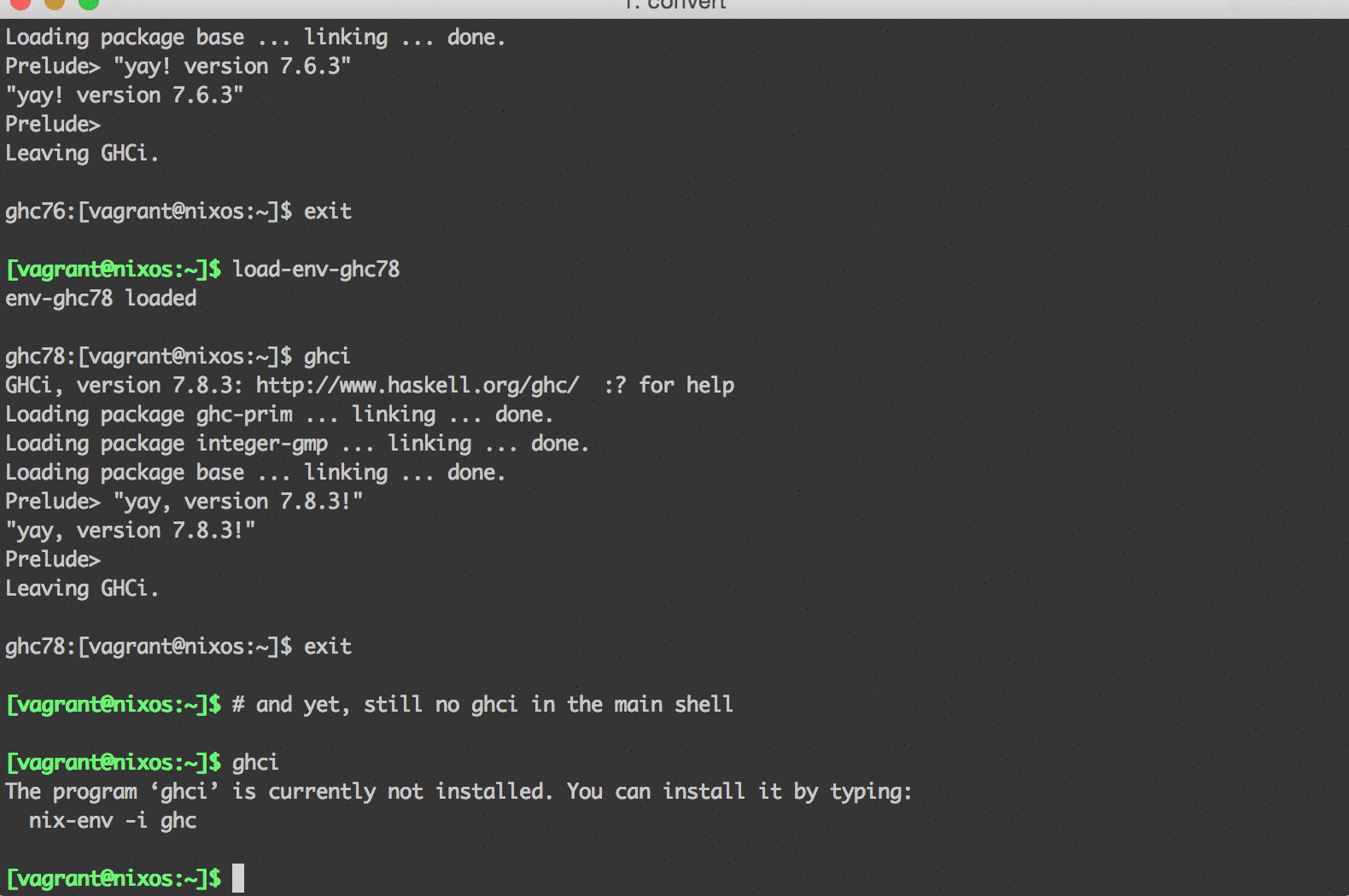
We can do this through a special file ~/.nixpkgs/config.nix, which may contain package overrides you’ve specified for your user. Here’s how you can create the file for the first time if you don’t already have one:
mkdir -p ~/.nixpkgs
touch ~/.nixpkgs/config.nixNext we’ll use the built-in packageOverrides to define one or more new myEnvFun environments. The below example is written in the Nix language. We won’t explain all of the syntax here, but we’re defining two new packages that can be installed; one that will allow us to use ghc at version 7.6, and one at 8.3.
# ~/.nixpkgs/config.nix
{
# ~/.nixpkgs/config.nix lets us override the Nix package set
# using packageOverrides. In this case we extend it by adding
# new packages using myEnvFun.
packageOverrides = pkgs : with pkgs; {
ghc76 = pkgs.myEnvFun {
name = "ghc76";
buildInputs = [ ghc.ghc763 ];
};
ghc78 = pkgs.myEnvFun {
name = "ghc78";
buildInputs = [ ghc.ghc783 ];
};
};
}Here’s how we can install the environments from our snippet above:
# nix-env will look for ~/.nixpkgs/config.nix and, if it exists, use the package
# overrides you've defined there
nix-env -i env-ghc76
nix-env -i env-ghc78Once they’re installed, there’s no need to reinstall them unless you uninstall them or make a change (for instance, maybe adding a new package to buildInputs).
Let’s load up our new ghc76 environment first:
$ load-env-ghc76
env-ghc76 loaded
ghc76:[vagrant@nixos:~]$ ghci
GHCi, version 7.6.3: http://www.haskell.org/ghc/ :? for help
Loading package ghc-prim ... linking ... done.
Loading package integer-gmp ... linking ... done.
Loading package base ... linking ... done.
Prelude>
Leaving GHCi.
ghc76:[vagrant@nixos:~]$ exitWhen you’re done you can exit back to your normal shell, which won’t have ghci installed (unless you specifically installed it for your user). Want to try out the environment with ghc 7.8.3 instead?
$ load-env-ghc78
env-ghc78 loaded
ghc78:[vagrant@nixos:~]$ ghci
GHCi, version 7.8.3: http://www.haskell.org/ghc/ :? for help
Loading package ghc-prim ... linking ... done.
Loading package integer-gmp ... linking ... done.
Loading package base ... linking ... done.
Prelude>
Leaving GHCi.
ghc78:[vagrant@nixos:~]$ exitIn practice, taking a few minutes to define these package sets has proven to be a fairly straightforward and reliable to keep project dependencies isolated. Perhaps best of all, you can keep your config.nix in a repo somewhere and use it on any machine where you need to reproduce those environments.
Want to start writing your own? Here are some tips:
- myEnvFun prepends “env-” to the “name” you give your environment
- ex. if you create a myEnvFun with name = “dev”, you can install with
nix-env -i env-dev - Nix lists are space delimited. want git and tmux?
buildInputs = [ git tmux ]; - installing the env adds a script to your path called load-env-name
- for our dev example we can now call
load-env-devto load the environment
Want to see it in action? Here’s a fancy animated gif demonstrating the environment switching.
Learning more
The Nix/NixOS community is growing, and they’ve been developing solutions and novel approaches to a great many packaging and deployment problems. There’s Nix the language (in order to write your own packages you should learn how to write Nix expressions), NixOS the Linux distribution (which lets you write NixOS modules, providing a config management-like layer), and a whole lot more.
Here are some resources for getting started:
1.Note that this only applies to where software is installed. If you install cowsay via apt-get and nix-env then your user’s $PATH will determine which one is used.
2.Unless you’re on OS X, where builds still require some globals that may change or cause breakage when upgrading to newer versions of OS X. There’s a ##nix-darwin channel on freenode working to address this if you want to contribute.
3.If you’re using the Nix unstable channels there are other kinds of build failures you may encounter, like unintentional backwards incompatibilities in upgraded packages (ex. foo only works because of a bug in bar, bar is upgraded with bug fix, foo stops building until the package maintainers can address it)
]]>
{kind=link}